分布式ID生成
简介
对大量数据进行唯一标记,唯一标记的生成成为关键
要求
- 全局唯一性
- 趋势递增(数据库主键索引结构为B-TREE,应该有序保证写入效率)
- 单调递增
- 不暴露业务信息
- 低延迟、高可用、高并发
方案
- UUID
- 数据库、Redis等单点服务
- 类snowflake算法
UUID
UUID大家都很熟悉了,这里只介绍一下优缺点
- 优点:
- 本地产生,无远程调用,延迟低
- 容易拓展,每台机器都可以直接使用
- 缺点:
- 无序,无法成为主键
- 不同机器实现方式不一致可能重复
- 信息不安全,基于MAC地址产生的可能造成MAC泄漏
单点服务
使用数据库或者Redis等单点服务生成递增的id
- 优点:
- 简单方便
- 全局单调递增
- 缺点:
- 强依赖单点服务
- 性能限制于单点服务
- 难以拓展
优化一 高可用单点服务,可能导致主从切换时重复id
优化二 使用多个机器,设置不同初始值,步长为机器总数,可能导致水平拓展困难、失去单调递增性、性能依旧限制于机器个数
优化三 每次从数据库取一个id段,id段使用完毕再从数据库再取一段,可能导致id不够随机、tps达到id段个数时出现性能尖刺、DB宕机无法使用
优化四 在优化三的基础上,本id段使用一定比例再取一个id段,id段使用完毕可以直接切换到下一个id段,避免尖刺,可能导致DB宕机无法使用
类snowflake算法
雪花算法大家也比较熟悉了,下面是雪花算法的id组成结构,这里谈一下优缺点和需要解决的核心问题
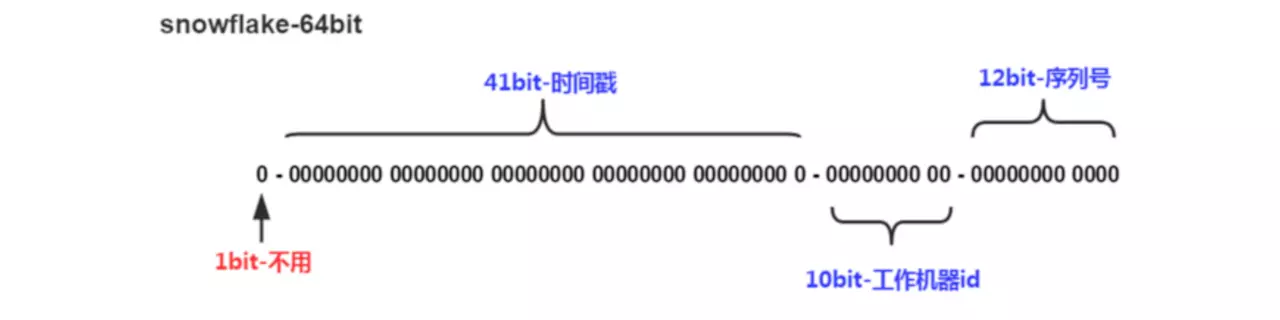
- 优点:
- 趋势递增
- 不依赖第三方,高可用,高并发(每一毫秒单机4096个id)
- 可修改每段bit个数适应应用系统
- 缺点:
- 趋势递增,非单调递增
- 强依赖时钟,时间回拨导致服务不可用或id重复
- 并发较小时,末尾为0的机率很大,分库分表取模后不均匀
解决时钟回拨问题
- 启动时判断自身时间与上次记录时间
- 启动时判断自身时间与其他机器时间平均值
- 每隔一段时间写入时间记录
- 每次生成id都与上次时间比较
- 时间较大回拨直接启动失败或停止服务
- 时间较小回拨可以等待